Standard Table is the most widely used table Type. It has performance drawbacks if not used properly.
Few months ago, I asked a question:
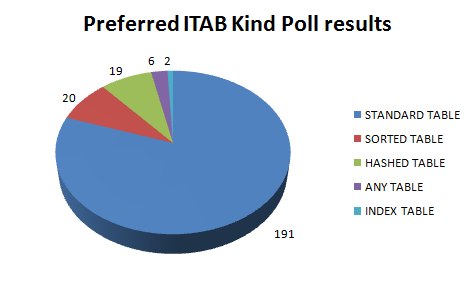
Your Preferred table kind for your ITAB
Total of 236 people has voted for the Poll.
Demo Program on ITAB Performance
Before we jump into the poll result, check out the small program and its performance result. Here I’m comparing the Performance of the READ on Internal tables – Standard VS Sorted VS Hashed VS Standard using BINARY.
Performance Comparison - ITAB TYPES
*&---------------------------------------------------------------------* *& Purpose : Performance Comparison between READ on various TYPEs of *& internal tables *& Author : Naimesh Patel *& URL : http://zevolving.com/?p=1861 *&---------------------------------------------------------------------* REPORT ZTEST_NP_TABLE_TYPE_PERF. * TYPES: BEGIN OF ty_vbpa, vbeln TYPE vbpa-vbeln, posnr TYPE vbpa-posnr, parvw TYPE vbpa-parvw, kunnr TYPE vbpa-kunnr, END OF ty_vbpa. DATA: t_std TYPE STANDARD TABLE OF ty_vbpa. DATA: t_sorted TYPE SORTED TABLE OF ty_vbpa WITH UNIQUE KEY vbeln. DATA: t_hashed TYPE HASHED TABLE OF ty_vbpa WITH UNIQUE KEY vbeln. TYPES: BEGIN OF ty_vbak, vbeln TYPE vbak-vbeln, found TYPE flag, END OF ty_vbak. DATA: t_vbak TYPE STANDARD TABLE OF ty_vbak. DATA: lt_vbak TYPE STANDARD TABLE OF ty_vbak. FIELD-SYMBOLS: <lfs_vbak> LIKE LINE OF t_vbak. DATA: lv_flag TYPE flag, lv_sta_time TYPE timestampl, lv_end_time TYPE timestampl, lv_diff TYPE p DECIMALS 5. data: lv_num_main type i, lv_num_sub type i. START-OF-SELECTION. lv_num_main = 50000. " Change for different number of records lv_num_sub = lv_num_main / 2. * SELECT vbeln FROM vbak INTO TABLE t_vbak UP TO lv_num_main ROWS. * SELECT vbeln posnr parvw kunnr INTO TABLE t_std FROM vbpa UP TO lv_num_sub ROWS FOR ALL ENTRIES IN t_vbak WHERE vbeln = t_vbak-vbeln AND parvw = 'AG'. * Copying into the Sorted and Hashed table t_sorted = t_std. t_hashed = t_std. *---- * READ on Standard Table GET TIME STAMP FIELD lv_sta_time. LOOP AT t_vbak ASSIGNING <lfs_vbak>. READ TABLE t_std TRANSPORTING NO FIELDS WITH KEY vbeln = <lfs_vbak>-vbeln. IF sy-subrc EQ 0. ".. ENDIF. ENDLOOP. GET TIME STAMP FIELD lv_end_time. lv_diff = lv_end_time - lv_sta_time. WRITE: /(30) 'Standard Table', lv_diff. * *---- * READ on Standard table with Binary Search GET TIME STAMP FIELD lv_sta_time. SORT t_std BY vbeln. LOOP AT t_vbak ASSIGNING <lfs_vbak>. READ TABLE t_std TRANSPORTING NO FIELDS WITH KEY vbeln = <lfs_vbak>-vbeln BINARY SEARCH. IF sy-subrc EQ 0. ".. ENDIF. ENDLOOP. GET TIME STAMP FIELD lv_end_time. lv_diff = lv_end_time - lv_sta_time. WRITE: /(30) 'Standard Table - Binary', lv_diff. * *---- * READ on Sorted Table GET TIME STAMP FIELD lv_sta_time. LOOP AT t_vbak ASSIGNING <lfs_vbak>. READ TABLE t_sorted TRANSPORTING NO FIELDS WITH KEY vbeln = <lfs_vbak>-vbeln. IF sy-subrc EQ 0. ".. ENDIF. ENDLOOP. GET TIME STAMP FIELD lv_end_time. lv_diff = lv_end_time - lv_sta_time. WRITE: /(30) 'Sorted Table', lv_diff. * *---- * READ on HASHED table GET TIME STAMP FIELD lv_sta_time. LOOP AT t_vbak ASSIGNING <lfs_vbak>. READ TABLE t_hashed TRANSPORTING NO FIELDS WITH TABLE KEY vbeln = <lfs_vbak>-vbeln. IF sy-subrc EQ 0. ".. ENDIF. ENDLOOP. GET TIME STAMP FIELD lv_end_time. lv_diff = lv_end_time - lv_sta_time. WRITE: /(30) 'Hashed Table', lv_diff.
I ran the program multiple times for different set of records. Here are the average values based on the performance readings:
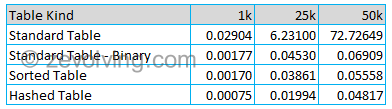
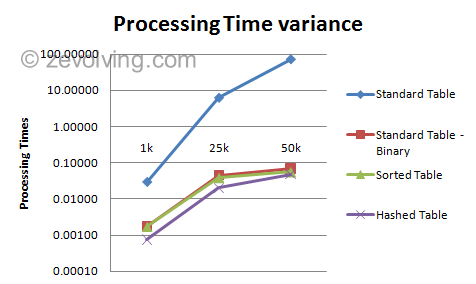
And on Graph
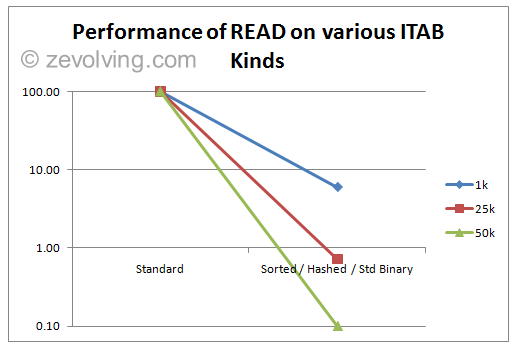
Yet on another graph, where Standard table readings are considered at benchmark of 100. I used average value for all other ITAB Types to show the tentative performance gain when Using another ITAB Type other than Standard Type.
Now let’s see the Poll Result
Most of the participants choose the Standard Table Type – by far Standard Table is the preferred table type.
As per the above program results & graph, you should carefully decide when to use which Table Type.
I did something like this when we went to 4.6D.
We generally use the standard table, sorted, and binary search. For most of our programs, we pass the itab along and make additions, subtractions, modifications and loops for certain sets of records before output. Can’t do that with a hashed table.
Also, standard table is easier for others to maintain the program without worrying whether the reads will be correct.
That said, I use hashed tables for any reference table and sorted for loop controls when I can.
Very nice post and graphics!
Hello Steve,
We can also change the entries in the HASHED and Sorted table but, it has to be accessed by a specific Key. The cost of updating HASHED table would be same irrespective of number of entries. Many of the times, we are not sure about the key and consider using the Standard table. When we have a performance crunch, we should be using HASHED table to improve the performance.
Glad you like the Graphics 😉
Regards,
Naimesh Patel