You would get insight from Performance perspective when not using the Keys in SELECT with FOR ALL ENTRIES. System would spend definitely more time when there mixture of Entries in the ITAB.
Problem
Once you have selected records from one table and need to get the relevant records from the dependent table, you generally use FOR ALL ENTRIES IN ITAB addition of the SELECT query. This would return you the entries which matched keys from your ITAB specified after FOR ALL ENTRIES.
Most of the time, people select the data in ITAB and use that ITAB to get the data from another table. Like, you select the Materials from Sales Order items VBAP and use FOR ALL ENTRIES to select description from MAKT for the selected Materials. At this point, many people just pass all the selected entries from VBAP as FOR ALL ENTRIES FROM LT_SO_ITEMS. This is usually a performance drainage.
While using the FOR ALL ENTRIES, system selects all the records which meets the where condition. Once the data is selected, it removes the duplicate entries. E.g. if you have 1000 entries in your LT_SO_ITEMS and you use it in FOR ALL ENTRIES, it would select the records from MAKT for all 1000 entries even though there are only few say 50 unique materials. After the data selection, DB removes the duplicate records and present you the description for 50 materials.
Solution
Whenever you need to use the FOR ALL ENTRIES, you must always consider getting unique keys first before doing the SELECT. It may appear unnecessary work, but believe me, it would save you lot of time. Refer to the statistics at end of this post to figure out the performance improvement.
To get the unique keys:
- Declare a key table type
- Declare a ITAB_KEYS with this type
- LOOP AT main ITAB and append entries in the ITAB_KEYS
- SORT and DELETE adjacent duplicates
There would be other ways to achieve the Keys – Collect the table, READ the table entries before appending in it.
Code Lines
Check out the code lines and the numbers to see the performance improvement achieved when you use Unique Keys. In the code lines, there are 3 different approach to select the data.
- Using the Mix keys. You selected the records, you used it directly in FOR ALL ENTRIES
- Getting the Unique keys by doing the DELETE adjacent duplicates and then use in FOR ALL ENTRIES
- Getting the Unique keys by READ and then use in FOR ALL ENTRIES
Report Z_PERF_FOR_ALL_ENTRIES
REPORT Z_PERF_FOR_ALL_ENTRIES. TYPES: BEGIN OF lty_matnr, matnr TYPE mara-matnr, END OF lty_matnr. DATA: lt_matnr TYPE STANDARD TABLE OF lty_matnr. DATA: lt_makt TYPE STANDARD TABLE OF makt. DATA: lv_sta_time TYPE timestampl, lv_end_time TYPE timestampl, lv_diff_w TYPE p DECIMALS 5, lv_diff_f LIKE lv_diff_w, lv_save LIKE lv_diff_w. DATA: lt_mix_matnrs TYPE STANDARD TABLE OF lty_matnr. DATA: lwa_mix_matnrs LIKE LINE OF lt_mix_matnrs. DATA: lt_unique_matnrs TYPE STANDARD TABLE OF lty_matnr. DATA: lwa_unique_matnrs LIKE LINE OF lt_unique_matnrs. * Prepare data SELECT matnr INTO TABLE lt_matnr FROM mara UP TO 10 ROWS. " Change the number to get different numbers DO 1000 TIMES. APPEND LINES OF lt_matnr TO lt_mix_matnrs. ENDDO. *------- * 1. Mix keys *------- GET TIME STAMP FIELD lv_sta_time. SELECT * FROM makt INTO TABLE lt_makt FOR ALL ENTRIES IN lt_mix_matnrs WHERE matnr = lt_mix_matnrs-matnr. GET TIME STAMP FIELD lv_end_time. lv_diff_w = lv_end_time - lv_sta_time. WRITE: /(30) 'Mix Keys', lv_diff_w. *------- * 2. Unique Keys - DELETE *------- GET TIME STAMP FIELD lv_sta_time. LOOP AT lt_mix_matnrs INTO lwa_mix_matnrs. lwa_unique_matnrs-matnr = lwa_mix_matnrs-matnr. APPEND lwa_mix_matnrs TO lt_unique_matnrs. ENDLOOP. SORT lt_unique_matnrs BY matnr. DELETE ADJACENT DUPLICATES FROM lt_unique_matnrs COMPARING matnr. SELECT * FROM makt INTO TABLE lt_makt FOR ALL ENTRIES IN lt_unique_matnrs WHERE matnr = lt_unique_matnrs-matnr. GET TIME STAMP FIELD lv_end_time. lv_diff_f = lv_end_time - lv_sta_time. WRITE: /(30) 'Uniqe Keys - delete', lv_diff_f. *------- * 3. Unique Keys - READ *------- CLEAR: lt_unique_matnrs. GET TIME STAMP FIELD lv_sta_time. SORT lt_mix_matnrs BY matnr. LOOP AT lt_mix_matnrs INTO lwa_mix_matnrs. READ TABLE lt_unique_matnrs TRANSPORTING NO FIELDS WITH KEY matnr = lwa_mix_matnrs-matnr BINARY SEARCH. IF sy-subrc NE 0. lwa_unique_matnrs-matnr = lwa_mix_matnrs-matnr. APPEND lwa_unique_matnrs TO lt_unique_matnrs. ENDIF. ENDLOOP. SELECT * FROM makt INTO TABLE lt_makt FOR ALL ENTRIES IN lt_unique_matnrs WHERE matnr = lt_unique_matnrs-matnr. GET TIME STAMP FIELD lv_end_time. lv_diff_f = lv_end_time - lv_sta_time. WRITE: /(30) 'Uniqe Keys - Read', lv_diff_f.
Statistics
I ran the report for different number of records. The numbers are like this:
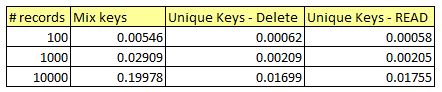
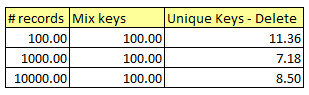
If we make time takes by mix keys as 100%, the time taken by unique keys would look like this:
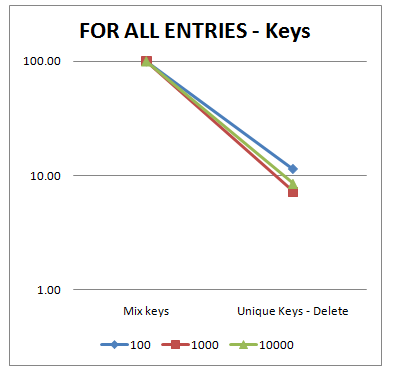
And on graph ..
More Performance Tuning tips in ABAP
Check out the other threads to learn more Performance Tuning in ABAP:
- Parallel Cursor – To speed up performance of Nested LOOP
- Parallel Cursor – 2: without using READ
- Use of Field-symbols vs Work area
- Measure the Performance between Break-Points using SE30
- READ-ONLY attribute vs GETTER methods
- Performance of ITAB Copy
- Performance of Using Keys in SELECT with FOR ALL ENTRIES
- ABAP Internal Table Performance for STANDARD, SORTED and HASHED Table
- ABAP Internal Table Secondary Key Performance comparison
- ABAP build a table with Unique Keys – Performance Comparison
- ABAP Parallel Cursor – Things to Remember
- Use of REFERENCE variable vs Workarea vs Field-Symbols
- FOR ALL ENTRIES – Why you need to include KEY fields
- ABAP Performance for DELETE on ITAB
- Write Green Programs
Instead of writing the code for sort and then delete duplicate keys…why can not we declare the table type as sorted and with unique key Matnr.
Hello Aman,
While writing it crossed my mind to declare the sorted table. But, the point of this post is to check the performance of the SELECT. I measured the performance from beginning of massaging the data to selecting it. If you have noticed, in both approach with unique keys, time saving is negligible.
Regards,
Naimesh Patel
Hey Naimesh:
If the internal table used in For all entries increase in size; the performance of the select decreases. The select can further be optimized by looping the select in small batches, say 1000 entries per batch. I have seen programs going resulting in short dump when FOR all entries was used on cluster tables like pcl4.
Regards
Navneet Saraogi
Navneet,
This was the example of how to call the for all entries, the amount of data is different from this concept. If the data subset is large while calling for all entries , then there are others measures to be taken as you said.
Naimesh – Nice one with easy language 😉
Kesav
Hello Navneet,
I agree with Keshav’s opinion. Here, I want to show how much performance can be improved when using the unique key.
I haven’t seen it going to runtime error even with about 1 million record. But I have surely seen it goes to dump when you use SELECT-OPTION or RANGE with about 20K entries within it.
Regards,
Naimesh Patel
Hello Naimesh,
Thanks for the nice blog!
One more point to improve the performance is COLLECT using:
COLLECT
And results:
Performance of Using Keys in SELECT with FOR ALL ENTRIES
Mix Keys 0,36966
Uniqe Keys – delete 0,02287
Uniqe Keys – Read 0,02687
Uniqe Keys – Collect 0,01924
Sorry for the one mistake!
Hier the correct code :
COLLECT
And results:
Performance of Using Keys in SELECT with FOR ALL ENTRIES (select with “UP TO 100 ROWS”)
Mix Keys 4,20297
Uniqe Keys – delete 0,19735
Uniqe Keys – Read 0,26005
Uniqe Keys – Collect 0,16717
Hello Pavel,
Thanks for adding the code lines using the COLLECT. This gives all of us a new dimension to think about. In all cases, we must use Unique keys when using FOR ALL ENTRIES.
Regards,
Naimesh Patel
Hai with this example i learnt a number of techniques to read the data and to play with the data … At last Pavel Gave a twist with simple collect statement…
Thank u all…
Same for me about learning something new.Thank you all.
I keep the definition of both table same i.e. lt_unique_matnrs, lt_mix_matnrs. copy data directly .
CLEAR: lt_unique_matnrs[].
lt_unique_matnrs[] = lt_mix_matnrs[].
sort lt_unique_matnrs by matnr.
DELETE ADJACENT DUPLICATES FROM lt_unique_matnrs COMPARING matnr.
SELECT * FROM makt
INTO TABLE lt_makt
FOR ALL ENTRIES IN lt_unique_matnrs
WHERE matnr = lt_unique_matnrs-matnr.
let me know your thoughts this approach.
Hey Naimesh,
just wanted you to know I pass around your blogs to the other ABAPERs where I work.
Thanks!
Hello Steve,
Thanks much for spreading the words about zevolving.com. Much appreciated.
Regards,
Naimesh Patel