DELETE on ITAB is widely used when you need to filter out the entries. Lets see the performance for different Delete statements.
DELETE on ITAB
Filtering entries from an internal table would be done using the DELETE itab WHERE condition.
There would be huge difference in performance is you don’t use proper type for the ITAB on which delete is being performed. For comparison, I have used different type of tables with DELETE.
This example contains the two internal table – Header and Item. For every 3rd record on header, all items would be deleted. This code lines is for setting up the data:
DATA: lv_flag TYPE flag, lv_sta_time TYPE timestampl, lv_end_time TYPE timestampl, lv_diff_w TYPE p DECIMALS 5, lv_diff_f LIKE lv_diff_w, lv_save LIKE lv_diff_w. TYPES: BEGIN OF ty_header, vbeln TYPE char10, field1 TYPE char50, END OF ty_header. TYPES: tt_header TYPE STANDARD TABLE OF ty_header. TYPES: BEGIN OF ty_item, vbeln TYPE char10, posnr TYPE char6, field2 TYPE char50, END OF ty_item. types: tt_item type STANDARD TABLE OF ty_item. DATA: t_header TYPE tt_header, t_item TYPE tt_item. PARAMETERS: p_num TYPE i DEFAULT 1000. START-OF-SELECTION. DATA: ls_header LIKE LINE OF t_header, ls_item LIKE LINE OF t_item. DO p_num TIMES. ls_header-vbeln = sy-index. ls_header-field1 = sy-abcde. APPEND ls_header TO t_header. DO 10 TIMES. ls_item-vbeln = ls_header-vbeln. ls_item-posnr = sy-index. APPEND ls_item TO t_item. ENDDO. ENDDO.
Using DELETE on standard table using WHERE
Now, lets delete the items using the “classic” DELETE using WHERE.
DATA: lv_mod_3 TYPE i. GET TIME STAMP FIELD lv_sta_time. SORT t_item BY vbeln. LOOP AT t_header INTO ls_header. lv_mod_3 = sy-tabix MOD 3. IF lv_mod_3 IS INITIAL. DELETE t_item WHERE vbeln = ls_header-vbeln. ENDIF. ENDLOOP. GET TIME STAMP FIELD lv_end_time. lv_diff_w = lv_end_time - lv_sta_time. WRITE: /(15) 'DELETE', lv_diff_w.
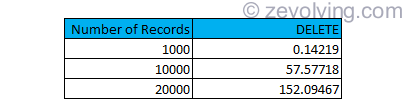
Processing time for DELETE
I ran the same code for multiple times, and timings are like these:
Using Parallel Cursor
Now, lets use some parallel cursor on this DELETE. This is similar to Parallel Cursor for the Nested Loop. First read the index of the required record, DELETE from that index on wards, till it finds a different key.
DATA: lv_mod_3 TYPE i. GET TIME STAMP FIELD lv_sta_time. SORT t_item BY vbeln. LOOP AT t_header INTO ls_header. lv_mod_3 = sy-tabix MOD 3. IF lv_mod_3 IS INITIAL. READ TABLE t_item TRANSPORTING NO FIELDS BINARY SEARCH WITH KEY vbeln = ls_header-vbeln. IF sy-subrc EQ 0. LOOP AT t_item INTO ls_item FROM sy-tabix. IF ls_item-vbeln NE ls_header-vbeln. EXIT. ENDIF. DELETE t_item INDEX sy-tabix. ENDLOOP. ENDIF. ENDIF. ENDLOOP. GET TIME STAMP FIELD lv_end_time. lv_diff_w = lv_end_time - lv_sta_time. WRITE: /(15) 'DELETE', lv_diff_w.
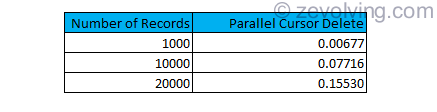
Processing time for DELETE
Obviously, the performance has to improve as parallel cursor is in play. The saving is surprisingly in range of ~95%.
Using SORTED table
Next test is using the SORTED table with Unique Key. Since this item table has unique key fields, I can easily define.
* Change type to sorted "types: tt_item type STANDARD TABLE OF ty_item. types: tt_item type SORTED TABLE OF ty_item with UNIQUE key vbeln posnr. * DATA: lv_mod_3 TYPE i. GET TIME STAMP FIELD lv_sta_time. SORT t_item BY vbeln. LOOP AT t_header INTO ls_header. lv_mod_3 = sy-tabix MOD 3. IF lv_mod_3 IS INITIAL. DELETE t_item WHERE vbeln = ls_header-vbeln. ENDIF. ENDLOOP. GET TIME STAMP FIELD lv_end_time. lv_diff_w = lv_end_time - lv_sta_time. WRITE: /(15) 'DELETE', lv_diff_w.
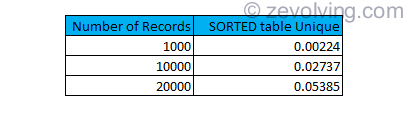
Processing time for DELETE on SORTED Unique Key
There is more performance improvement when using the SORTED table with unique key. Sorted tables are much more performance efficient as what we have seen in ABAP Internal Table Performance for STANDARD, SORTED and HASHED Table.
Using Secondary Key non-unique key
Since ABAP 731, Secondary key on the ITAB can be declared. This would be also helpful and increase the performance if you don’t have clear key.
"types: tt_item type STANDARD TABLE OF ty_item. "types: tt_item type SORTED TABLE OF ty_item with UNIQUE key vbeln posnr. TYPES: tt_item TYPE SORTED TABLE OF ty_item WITH UNIQUE KEY vbeln posnr WITH NON-UNIQUE SORTED KEY key2nd COMPONENTS field2. DATA: lv_mod_3 TYPE i. GET TIME STAMP FIELD lv_sta_time. LOOP AT t_header INTO ls_header. lv_mod_3 = sy-tabix MOD 3. IF lv_mod_3 IS INITIAL. DELETE t_item USING KEY key2nd WHERE field2 = ls_header-vbeln. ENDIF. ENDLOOP. GET TIME STAMP FIELD lv_end_time. lv_diff_w = lv_end_time - lv_sta_time. WRITE: /(15) 'DELETE', lv_diff_w.
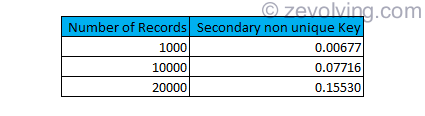
Processing time for DELETE with Secondary Key
The numbers are almost same as Parallel cursor approach.
On Graph
Putting all together. Needed to change the scale to log10 in order to display the difference.
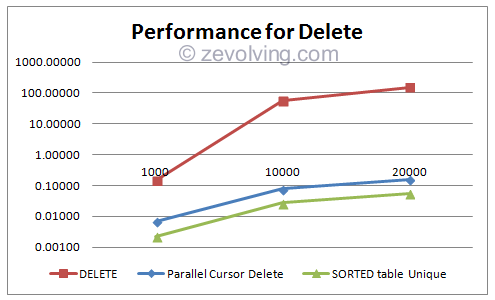
If DELETE with standard table is considered 100%, the other two options finishes the work in less than 0.15% time of that 100%.
Nice Analysis Naimesh!! The graphs makes the analysis better..
I was wondering if you could add one more in the list of comparison; in parallel cursor technique where we mark the items to be deleted and delete them outside the loop.
LOOP AT t_header INTO ls_header.
lv_mod_3 = sy-tabix MOD 3.
IF lv_mod_3 IS INITIAL.
READ TABLE t_item TRANSPORTING NO FIELDS
BINARY SEARCH
WITH KEY vbeln = ls_header-vbeln.
IF sy-subrc EQ 0.
LOOP AT t_item ASSIGN FROM sy-tabix.
IF -vbeln NE ls_header-vbeln.
EXIT.
ENDIF.
* Mark the Item data for deletion
CLEAR: -vbeln.
ENDLOOP.
ENDIF.
ENDIF.
ENDLOOP.
DELETE t_item[ ] WHERE vbeln is INITIAL.
Raju – I think it would not be very good from performance. Two main reasons:
Parallel Cursor technique using the INDEX to delete
DELETE with WHERE VBELN is INITIAL would have to scan the entire table to delete the items
I would try to add the code and its performance measurement.
Regards,
Naimesh Patel
Yes Naimesh.. I also think so.. Since you already have the numbers for others, just wanted to have the quantitative analysis as to where it falls in the graph.. 🙂
Hi Naimesh,
I want to delete the data from one internal table based on company code. Let say we have one table called RESULT_PACKAGE, In that table i have different company code data. Now i want to have only one company code data.
I want to use the parallel cursor technique. Now my question is can we write loop inside the another loop with the same internal table. Can we have any performance impact. Please provide your valuable input.
Thanks & Regards,
Chandra.
Chandra – You should be able to use parallel cursor technique to delete by using logic similar to this:
I haven’t wrote this in the system so there might be some syntax errors…
Regards,
Naimesh Patel
Hi Naimesh,
Thanks for the input. Now i got it.
One more query :
How to delete the records which has blank records.
Like
DELETE RESULT_PACKAGE WHERE divison NE ‘ ‘.
Can we achieve this through parallel cursor ?
Regards,
Chandra.
You can do that using the same technique as you can do for single company code. Just pass the blank value for the required field and you would be set ..
Regards,
Naimesh Patel
Thank you so much Naimesh…..
Regards,
Chandra.
Hi Naimesh,
I did some analysis for DELETE within LOOP using Parallel cursor and DELETE outside LOOP after marking in LOOP.
Strangely, one DELETE outside the LOOP gave better performance. Seems the cost of re-indexing in LOOP takes away the advantage of Parallel Cursor Technique and index wise DELETE. I tried to mention the details in this post. Please check it at your convenience.
http://www.sapyard.com/deleting-rows-of-the-internal-table-within-the-loop-is-it-a-taboo-a-big-no-no/
Can you please confirm if you get the same result if you delete the driver table within the LOOP.
Regards,
Raju.
Hello Raju,
Humm. There would be added cost for regenerating the index. I would have to run that scenario with my logic. I would update the post with the numbers.
Thanks,
Naimesh Patel
Thanks Naimesh..
If we delete some other internal table in LOOP using Parallel Cursor technique, it might be better. But if the driver internal table is being deleted, it might have some cost.
Waiting for your updated post.
Regards,
Raju.
[…] going through Naimesh’s post on performance on DELETE, I wondered how would deleting the entries of the table on which we […]
Hi Naimesh,
Need info regarding the internal table sorting.
Let’s say i have one internal table with structure fields like
calmonth,site,customer,salesman,date0,routeid
Now i have created internal table let’s say itab and i have sorted the internal table like
In this case how the internal table sorting and delete duplicates will work as the sequence of the field is changed in the sorting and deleting.
Need ur valueable input..
Many thanks,
Regards,
RaviChandra.
@Ravi Chandra,
The DELETE ADJACENT will not produce expected result as the sorting and the delete has different fields. For DELETE ADJACENT to work, the table should be sorted by the same fields. If they are not sorted using the same fields, rows of the table would be in different order.
From SAP Help:
http://help.sap.com/abapdocu_740/en/abapdelete_duplicates.htm
Thanks,
Naimesh Patel
Hi Naimesh – I think for the example of Ravi, the SORT and DELETE ADJACENT DUPLICATE would still work. The DELETE ADJACENT is still in the same sequence as his SORT. Only one field of the SORT which is in descending order is not used there in DELETE.
So if there are two entries with the same calmonth site customer salesman routeid but different date0, then the first entry with highest date0 (as sorted in descending order) would remain and the other would delete.
Your thought please.
@ Ravi, did you debug and check?
Regards,
Raju.
oops.. Yes you are right Raju that the sequence is correct.
In this case the biggest value for the DATE0 would be left in the table after the DELETE adjacent using all other fields.
Fields for delete adjacent doesn’t need to be in the sequence of how they were defined in the type or the structure. As long as the fields after DELETE adjacent has SORT with same fields (or more), you can get the explainable results.
Regards,
Naimesh Patel
Hi Naimesh & Raju,
Thank for the reply.
The sequence of sorting and deleting is same. But my concern is the sequence in the internal table structure is different to the sorting sequence.
Will it have any impact ?
Many thanks,
Regards,
RaviChandra.
Hi Naimesh & Raju,
Can you pls elaborate more on this. As i think there might be some performance issue, since the fields in the structure is different to the sorting and deleting statement.