Since HANA uses a different underlying architecture, there would be some impact to the custom ABAP Code. Check it out on what you need to do for HDB Migration?
What is HANA DB?
It’s very small section to describe what is HANA DB. But at a high level, these are different changes in HDB compared to other DBs:
- Column based database – Data is stored by Columns instead of rows
- Data is stored using the numeric keys – Numeric keys with Key value mapping tables for each character field provides the faster data selection
- Inbuilt Parallel processing
- No need for Secondary indexes
- and many more
So, many of the SAP long time (and obviously short term) Customers are ditching their existing DB for HANA DB. Take a deep dive on what needs to happen before and after, and what should happen after that.
ABAP Custom Programs and HANA
First of all, we would need to make sure that the custom ABAP programs can work on HANA DB. It is not the compilation errors, but rather errors from the functionality perspective. For this purpose, SAP has provided this variants in Code inspector (SCI). We should take all the custom objects, and run these two checks.
- FUNCTIONAL_DB
- FUNCTIONAL_DB_ADDITION
Variant FUNCTIONAL_DB
These are different checks would be performed:
- Finding Native SQL
- Database (DB) hints
- Finding ADBC (ABAP Database Connectivity) Usages
- Finding usages of special DDIC function modules that check or return the existence or technical properties of certain DB indexes.
- Finding accesses to technical pools/clusters of a pool/cluster table
- Finding non-robust ABAP code that relies on non-ensured/implicit sorting of certain SQL queries, although no ORDER BY clause is used. There are two different checks available for finding non-robust ABAP code:
- “Search problematic statement…w/o ORDER BY”
- “Depooling/Declustering: Search for…w/o ORDER BY ”
Variant FUNCTIONAL_DB_ADDITION
These additional checks addition to Functional DB checks.
- Checking SQL Operations without a WHERE Clause
- Checking SQL operations with the addition FOR ALL ENTRIES IN
, whereby in the code itself it is not ensured that the internal table < itab> is always filled. - Checking settings in DDIC tables for consistency. In particular, this checks whether table buffer settings have been maintained in a consistent manner (influence on performance).
More information – https://help.sap.com/saphelp_nw74/helpdata/en/2b/99ce231e7e45e6a365608d63424336/content.htm
Create Code Inspector Checks
Once you are on proper support pack, you want to get the latest variants. You can do that from the SCI – Code Inspector.
Use the menu option Utilities > Import Check Variants:
After a while, the message would appear to let you know that the new variants are imported.

Now you can see the check variant in the dropdown:

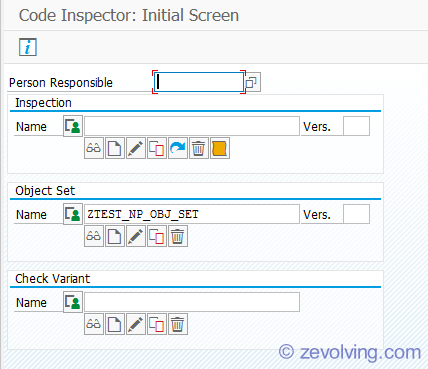
Once the code inspection checks are imported, create the object set.
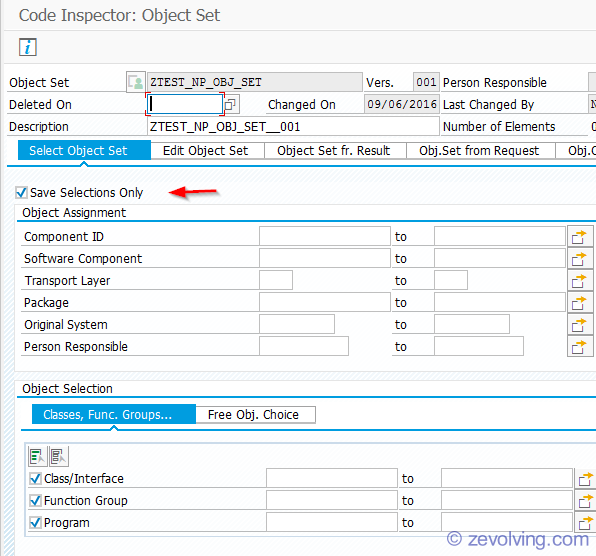
Select the option “Save Selections Only” check while you create the object set. What this would do is, it will not create the Object set right away, but it would create the actual set – by pulling the different objects – when you run the Inspection.
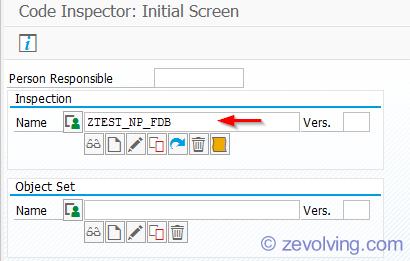
Now create the Inspection. Create three different inspections – each for the check variant. I use the naming convention like FDB for FUNCTION_DB, FDBA – FUNCTION_DB, and PDB – PERFORMANCE_DB.
Executing the Checks remotely
Many times, you run into situation where you have the SCI code inspector checks but that not the system which contains your code base. Like you have a BW system which was upgraded earlier but your ECC system is not yet upgraded. So, if you want to start the custom code review process, you should start the remote comparison.
Basically, in this you scenario, you create some tables in the system where you can run the checks. Lets say system U. Once these tables are created in system U, you connect the RFC and try to bring the data from system N. System N is not yet upgraded. Get the all the Custom code from the system N to system U. Run the checks in the system U and get the check results.
You can read more at – Executing Remote Static Checks in Context of HANA Migration
Performance improvements
Once all the issues in the step 1 – FUNCTION_DB & FUNCTION_DB_ADDITION are fixed, the focus would be on how to make the custom objects run better.
For that, we need to have the high running SQL queries. This can be done using the SQL Monitor (https://help.sap.com/saphelp_nw74/helpdata/en/f1/be2e59f44d448180703d6a497ec1e2/content.htm). We should run into for a week (no performance impact as it uses the async collector to collect the data), and for different time frames – period end, quarter end, year end etc. Once we have the SQL list, we can export that from Production to Development.
In development, we need to run the PERFORMANCE_DB check in SCI for the programs determined from the SQL monitor. The output from both of the result set can be combined to create one result set. This should be the set – on which we want to concentrate.
The Result of the PERFORMANCE_DB checks would have suggestion on how to improve certain queries – say by using the Join, avoiding the secondary key, using the subquery, using the DB procedure etc.
Useful Links
These are few links which you want to explore.
Thanks for Sharing,Nice start to road map.
Regards
Mohinder
Nice article to learn. Thanks for the post.
By any chance, is there a batch job to schedule the SCI check for all custom programs to check for issues using the two variants? Or it has to be individual?
Regards,
Raju.
Very useful. Keep it up!!
Great article thx 🙂
I am thinking rather than fixing codes, it is better to pushdown all abap codes to HANA layer via AMDP to make it more efficent.
In ABAP you are limited with internal table loops, no matter you use hash table, secondary indexes or whatever still it is slow.
Main advantage of HANA is, you can still use select queries over your temporary tables (internal table) in the HANA procedures which already AMDP classes allows you to do it 🙂
based on your HANA version, you can choose your engine which should work also during select query. it is very flexible.
With this method, 10 million rows (14 columns(bpc dimensions) unique records) currency conversion runtime for a BPC implementation decreased from 2hour+ to 2min 37 seconds including infocube(model) update.
Hello Bilen,
Yes, agree. That kind of analysis (and changes, hopefully) needs when you are in the Performance testing phase of the project. So far I have seen clients where the immediate attention is to fix the Functional errors (explicit sorting, Select on cluster, and things like that). The performance is an ongoing task and would require big changes, hence many clients try to avoid it during the upgrade phase itself.
Thanks.
Thank You for giving Such a Information. Please give this type of information. It’s Useful to all Learners.